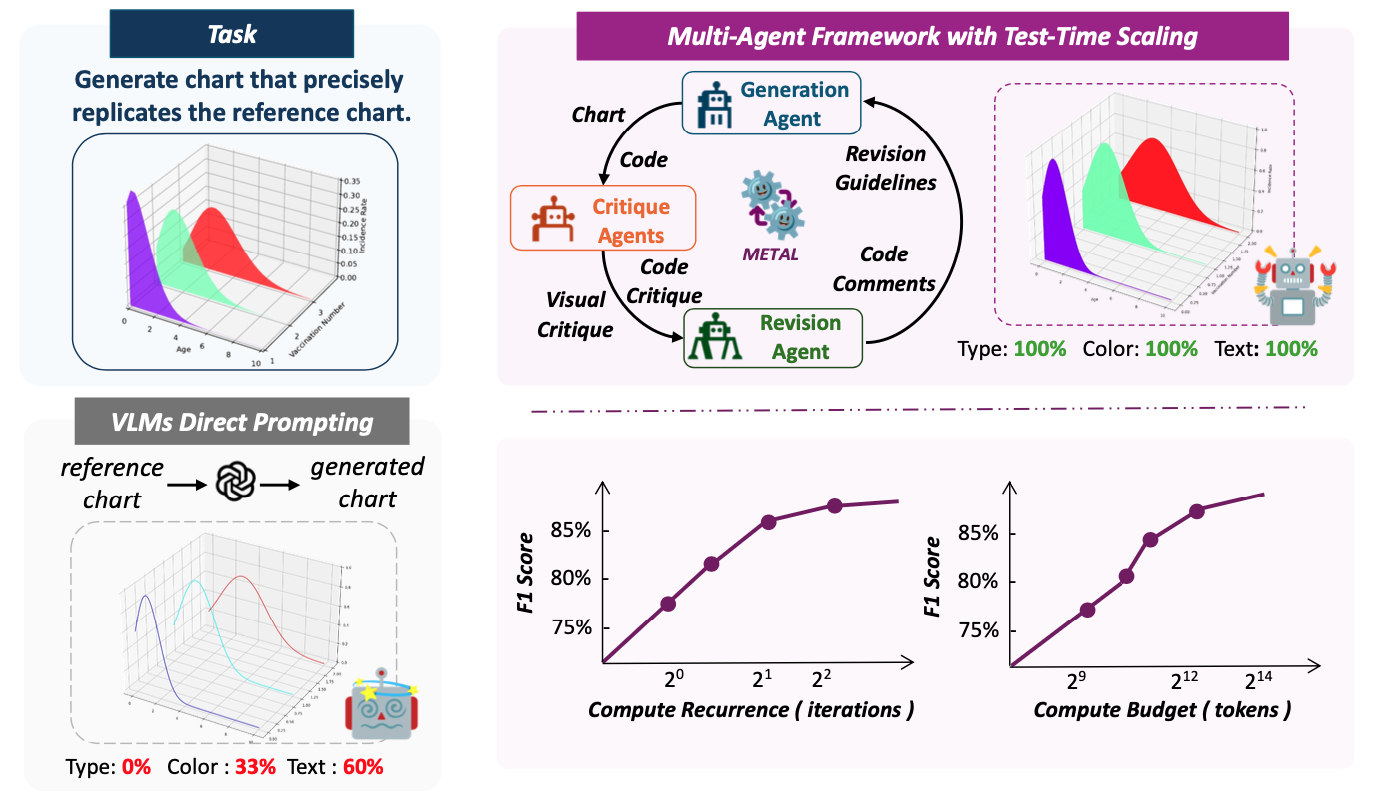
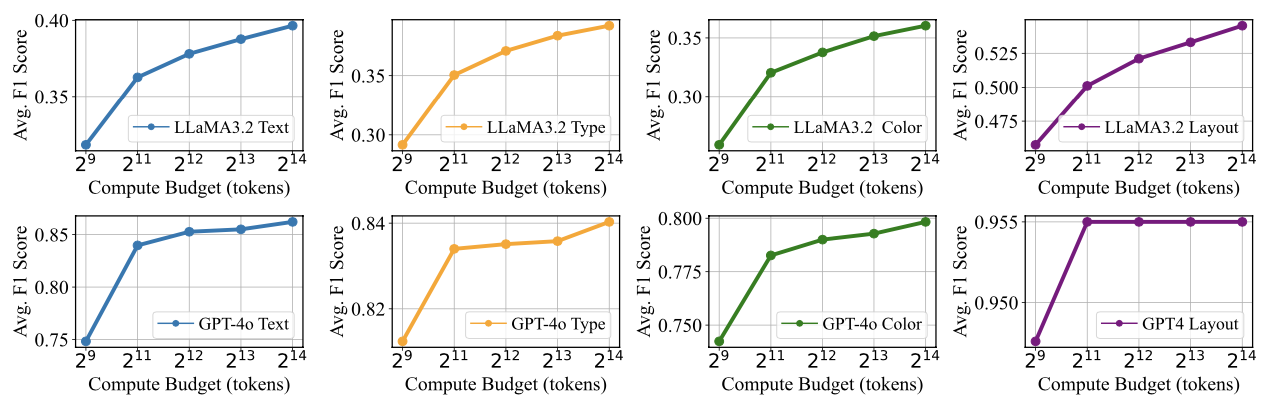
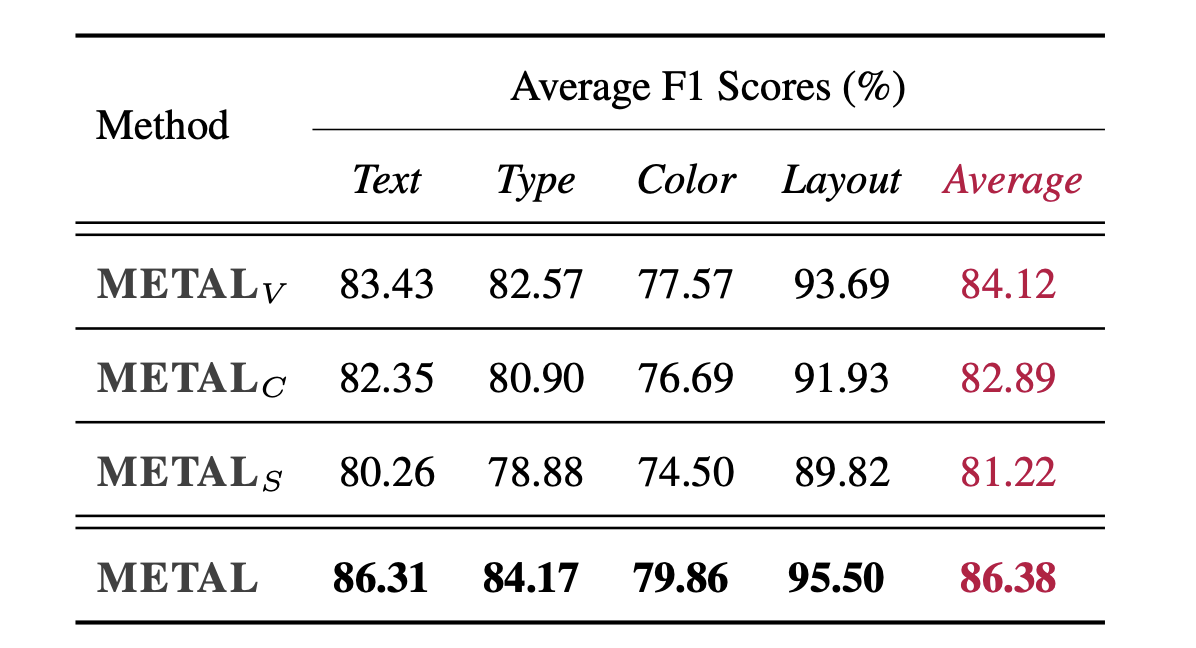
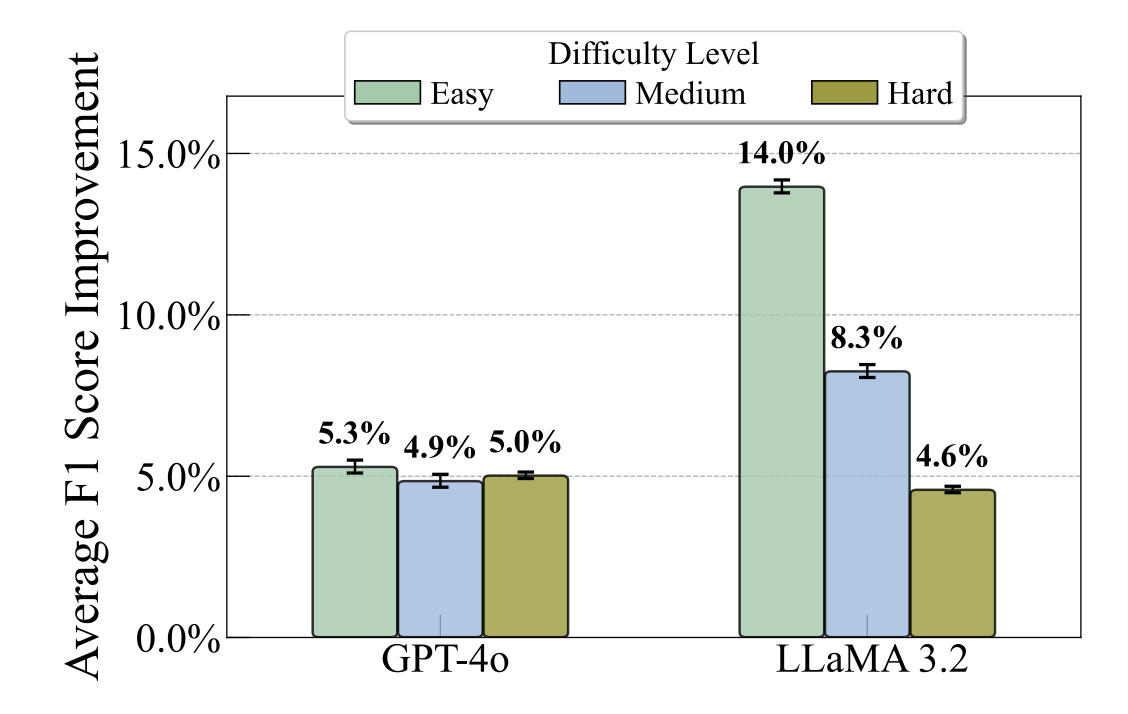
Chart generation aims to generate code to produce charts satisfying the desired visual properties, e.g., texts, layout, color, and type. It has great potential to empower the automatic professional report generation in financial analysis, research presentation, education, and healthcare. In this work, we build a vision-language model (VLM) based multi-agent framework for effective automatic chart generation. Generating high-quality charts requires both strong visual design skills and precise coding capabilities that embed the desired visual properties into code. Such a complex multi-modal reasoning process is difficult for direct prompting of VLMs. To resolve these challenges, we propose METAL, a multi-agent framework that decomposes the task of chart generation into the iterative collaboration among specialized agents. METAL achieves 5.2% improvement in accuracy over the current best result in the chart generation task. The METAL framework exhibits the phenomenon of test-time scaling: its performance increases monotonically as the logarithmic computational budget grows from 512 to 8192 tokens. In addition, we find that separating different modalities during the critique process of METAL boosts the self-correction capability of VLMs in the multimodal context.
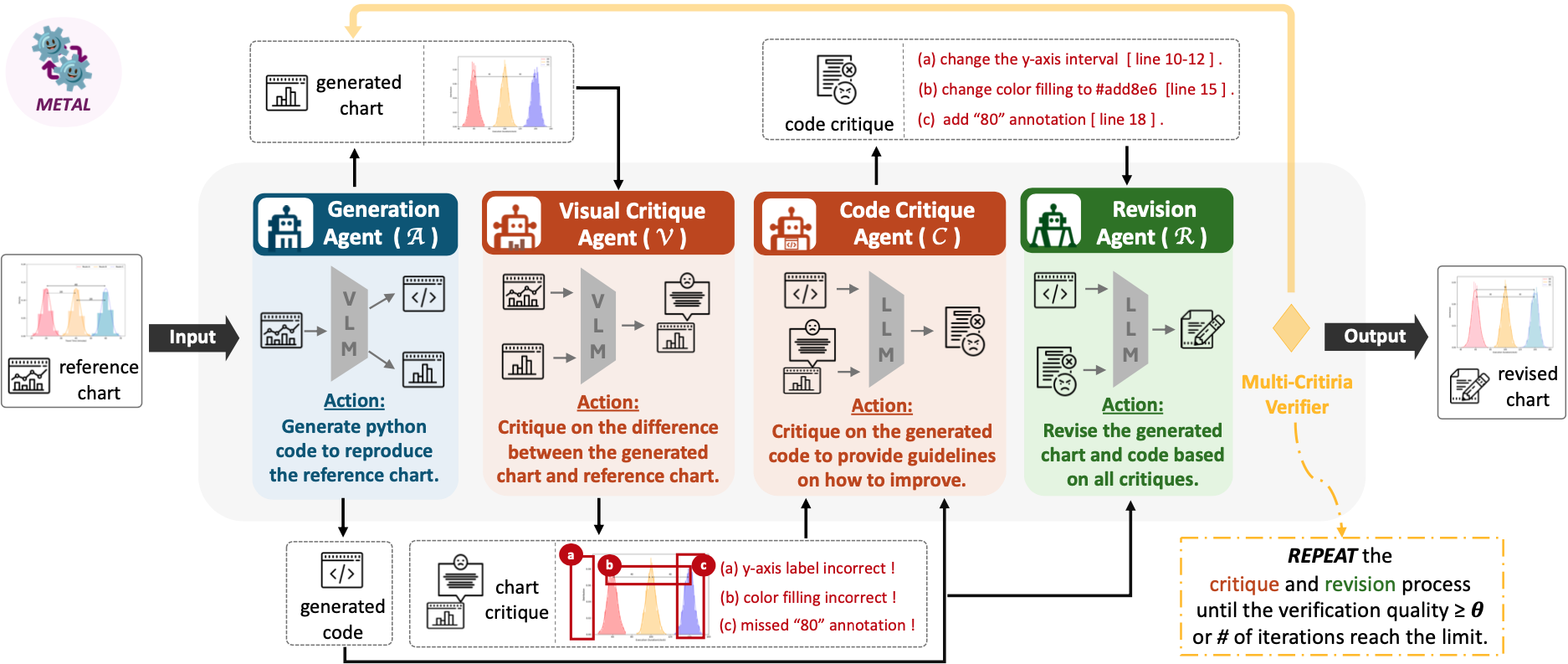
As shown in the figure, METAL is multi-agents system that consists of four specialized agents working in an iterative pipeline: (1) Generation Agent creates initial Python code to reproduce the reference chart, (2) Visual Critique Agent identifies visual discrepancies between the generated and reference charts, (3) Code Critique Agent analyzes the code and provides specific improvement guidelines, and (4) Revision Agent modifies the code based on the critiques. During inference, METAL iteratively refines the generated code until the rendered chart meets a predefined quality threshold or reach maximum attempts limit.
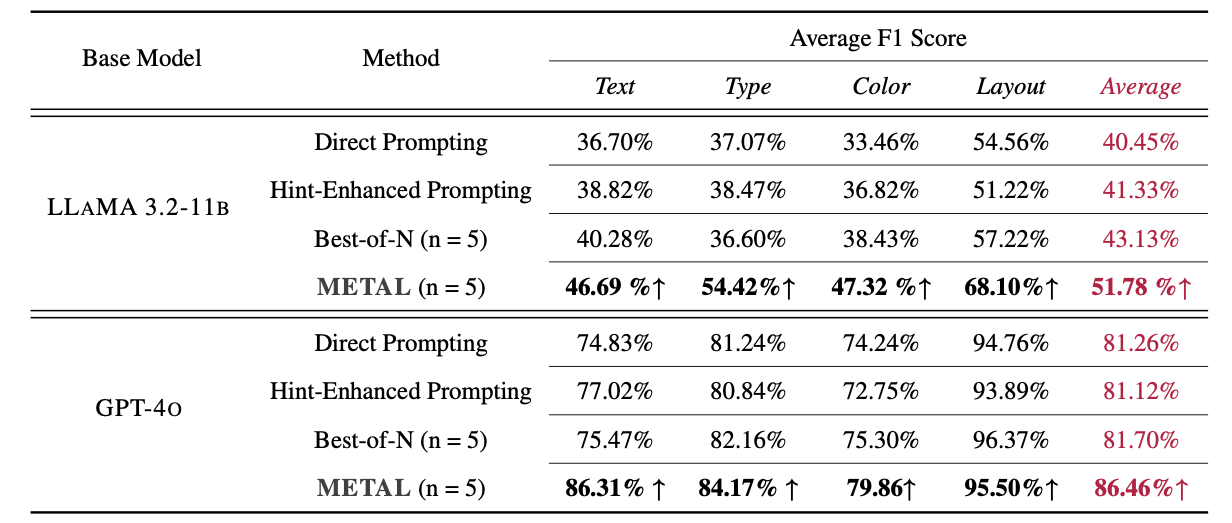
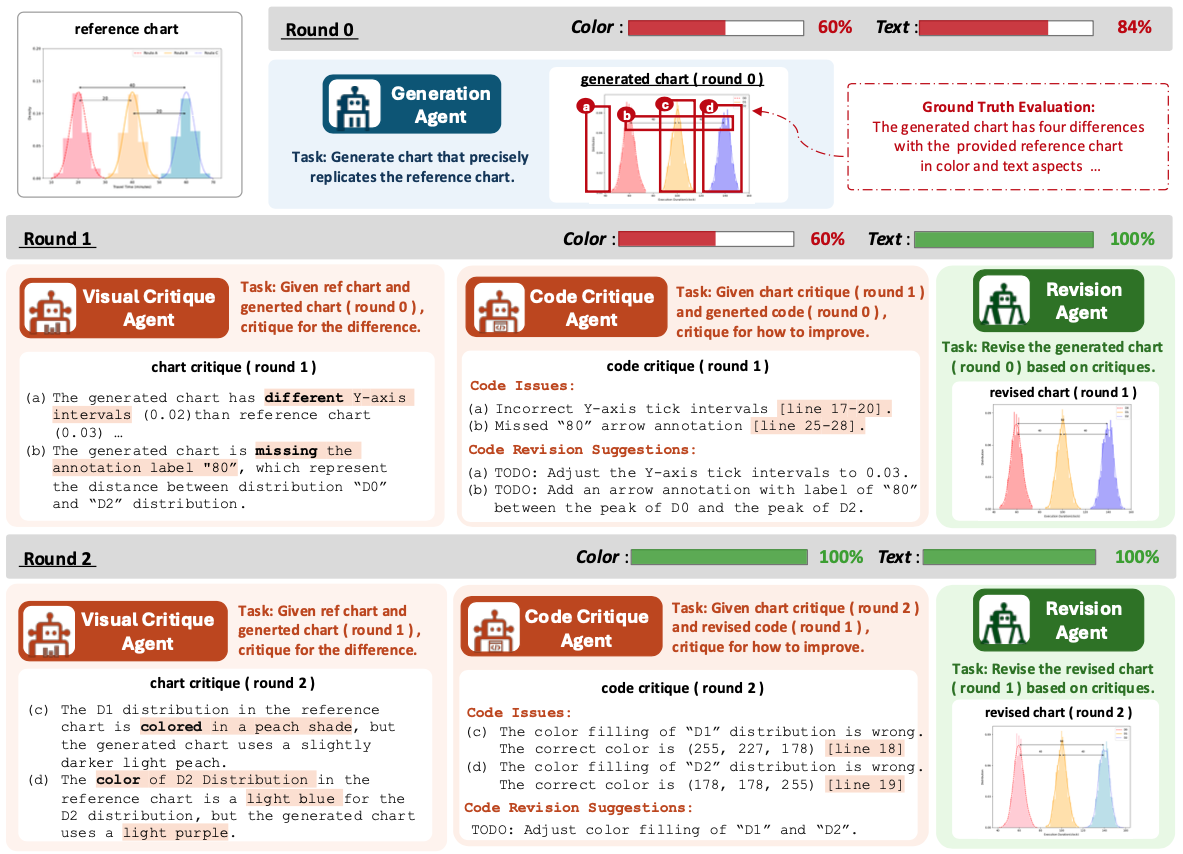
Case study of METAL’s progressive refinement from initial generation to perfect accuracy. Starting from Round 0’s initial generation (60% color accuracy, 84% text accuracy), the system iteratively improves the output. In Round 1, the system identifies and corrects Y-axis scale issues and missing annotations, achieving 100% text accuracy. Round 2 refines the color representations of distributions, achieving perfect accuracy across all metrics.
@misc{li2025metalmultiagentframeworkchart,
title={METAL: A Multi-Agent Framework for Chart Generation with Test-Time Scaling},
author={Bingxuan Li and Yiwei Wang and Jiuxiang Gu and Kai-Wei Chang and Nanyun Peng},
year={2025},
eprint={2502.17651},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2502.17651},
}